Regularization
정규화는 모델의 일반화 능력을 향상시키기 위한 중요한 기법중 하나로,
모델이 학습데이터에만 맞춰진 overfitting 학습을 방해 및 규제하여, 일반화 증진을 하는 것이 그 목적이다.
즉 모델이 학습 데이터에만 잘 적용되는 것이 아니라 테스트 데이터나 실제 새로운 데이터에도 잘 일반화되도록 모델을 조정하는 과정이다.
아래 다양한 종류의 정규화 기법들을, 실제 딥러닝 모델링 할때 상황에 맞게 취사 선택해가면서 적용해볼 수 있다.
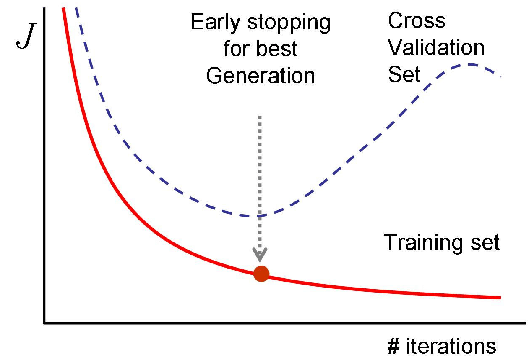
1) Early stopping
Early stopping은 모델이 과적합될 때 학습을 조기에 멈추는 기법이다.
학습을 멈출때에 validation 에러를 이용해서, training에 포함되지 않은 valid 데이터의 loss가 커지기 시작하는 시점에 학습을 멈추는 원리이다.
2) Parameter norm penalty
Parameter norm penalty는 뉴럴 네트워크 파라미터가 너무 커지지 않도록, 가중치(weight)를 제한하여 과적합을 방지하는 기법이다.
(== Weight decay 가중치 감소 효과)
각 파라미터의 값을 제곱해서 더한 값을 기준으로, L1 또는 L2 norm penalty를 사용하여 가중치의 크기를 제한한다.

뉴럴네트워크가 만들어내는 함수의 공간 (function space) 에서 최대한 그 공간을 부드럽게 만든다는 개념으로,
부드러운 함수일 수록 일반화 성능이 높다는 것을 전제한다.
(It adds smoothness to the function space)
3) Data augmentation
뉴럴네트워크, ml, dl에서 데이터가 매우 중요한데, 데이터가 무한히 많으면 일반화가 더 잘된다.
아무리 좋은 딥러닝 모델이라도 데이터가 적으면 머신러닝 기본 모델 (SVM, RF) 보다도 성능을 내기 어려움.
따라서 데이터를 증강해서 더 많은 데이터를 생성해내는 데이터 증강 (augmentation) 기법을 사용한다.
(More data are 'always' welcomed)
레이블이 변환되지 않는 조건 하에서, 다양하게 데이터를 증강시키는 것이 중요.

4) Noise robustness
Noise robustness는 모델이 입력 데이터의 노이즈에 강건하도록 만드는 기법으로, 주로 데이터에 노이즈를 추가하거나 노이즈 제거 기법을 사용하여 모델을 학습시킨다.
데이터 증강과의 차이라면, 노이즈를 input 데이터에만 집어넣는 것이 아니라, weights에도 집어넣는다는 점이다.
모델의 가중치를 초기화 할때 혹은, 학습 과정 중에 가중치(weight)를 조정할 때 무작위로 선택된 작은 값의 노이즈를 포함시키면,
모델이 학습하는 동안 노이즈에 민감해지고, 더욱 일반적인 패턴을 학습할 수 있게 된다.
입력데이터나 weight에 노이즈를 주입하면 네트워크 / 모델이 테스트 단계에서 더 좋은 성능을 낼 수 있다.

5) Label smoothing
데이터 증강과 비슷한 개념으로, Training 데이터에서 샘플 서로 두개를 뽑아서 서로를 섞어주는 개념 (Mix-up)이다.
(Mix-up constructs augmented training examples by mixing both input and output of two randomly selected training data)
특히 분류 문제의 경우, 서로 다른 라벨의 decision 바운더리를 찾고 결정하는 것이 핵심인데,
그 분류의 바운더리를, 부드럽게 만들어주는 효과가 있다. Mixup, CutMix 작업 등.
Mixup이란 이미지 자체를 섞어서 모호하게 블렌딩하는 것, Cutmix는 서로 일부를 떼어 그림을 조합하는 것.
아래 논문에서도 성능 향상 확인 가능하지만, 경험적으로도 분류 문제에서 두 기법의 성능 향상 효과가 뛰어난 편.

6) Dropout
Dropout은 신경망의 일부 뉴런을 무작위로 제거하여 과적합을 방지하는 기법으로,
뉴럴 네트워크의 일부 weight를 0으로 바꿔준다.
각각의 뉴런들이 확률적으로 제거되면서, 모델이 여러 가지 뉴런 조합에 적응하게 됨으로써, 보다 robust한 모델을 얻는 앙상블 효과를 얻을 수가 있다.

7) Batch normalization
Batch normalization은 신경망의 각 레이어에 대한 입력을 평균과 분산으로 정규화하여,
학습을 안정화하고 그래디언트 소실이나 폭주를 방지하는 기법이다. 이를 통해 네트워크가 더 빠르게 학습되고 더 나은 성능을 발휘할 수 있다.
('Batch normalization compute the empirical mean and variance independently for each dimension(layers) and normalize')

일반적으로 경험적으로 레이어가 깊게 쌓아진 경우 Batch normalization을 하면 성능이 많이 올라가지만,
처음 논문에서 제기했던 internal covariate shift 가 일어남으로써 성능이 좋아졌다는 주장에는 논란이 있다.
(Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (2015))
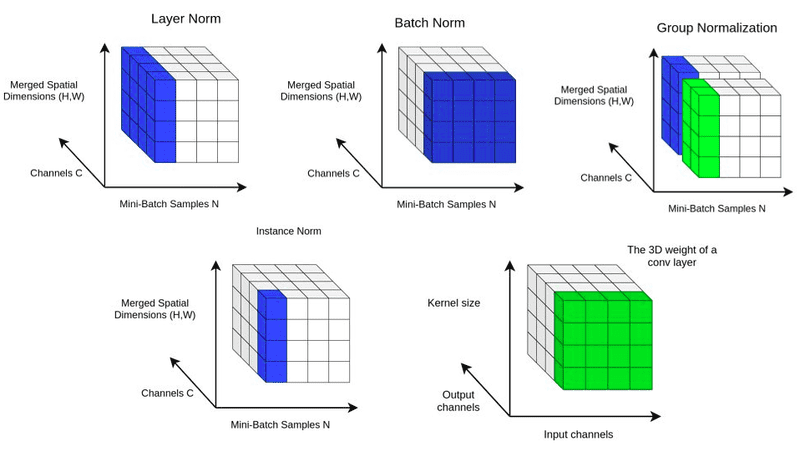
Batch normalization의 variances에는 아래와 같이 다양한 종류가 있다.
Batch 단위로 normalize한것 뿐이 아니라, layer를 기준으로, instance(데이터) 당 기준으로, group 기준으로 정규화 하기도 한다.
(Group Normalization (2018))
딥러닝 모델을 만들때, 다양한 normalization을 실험해보면서 가장 성능 좋은 케이스를 선택해볼 수 있을 것.
'ML study' 카테고리의 다른 글
| Long Short Term Memory (LSTM)— Improving RNNs (0) | 2024.06.05 |
|---|---|
| [네이버AI class] 6주차 (4) - 경사하강법 & Optimizer 종류 (0) | 2024.06.04 |
| [네이버AI class] 6주차 (3) - 최적화 주요 용어 (0) | 2024.06.03 |
| [네이버AI class] 6주차 (2) - MLP 뉴럴 네트워크 (1) | 2024.06.03 |
| [네이버AI class] 6주차 (1) - 딥러닝 기본 및 Historical review (0) | 2024.06.02 |