딥러닝 기본
딥러닝을 학습 할 때 중요한 것
- Implementation skill이 중요 : Pytorch, Tensorflow
- 수학적인 배경 : 선형대수, 확률론 중요
- 트렌드 논문들 및 연구들을 확인하는 것 중요
딥러닝은 neural network를 활용하는 머신러닝으로 , AI의 기법중 하나로 보면 됨.
딥러닝의 기본 요소 : 데이터 + 모델 + 손실함수 + 최적화 알고리즘
1) 데이터 (Data) : 풀고자하는 문제에 따라 다름
(ex. image classification, semantic segmentation, detection, pose estimation, visual q&a)
2) 모델 (Model) : 이미지, 텍스트 등 데이터가 주어졌을 때 그 데이터를 변환 및 분석하는 모델
같은 데이터, task가 다르더라도 모델에 따른 결과가 다름
(ex. Alexnet, ResNet, GoogleNet, LSTM, AutoEncoders, GAN..)
3) 손실함수 (Loss Function) : 모델을 어떻게 학습할지? 의 문제
딥러닝에서는 neural network에 들어있는 각 뉴런의 weight 와 bias, 각 정보를 어떻게 업데이트할지 기준이 되는 손실함수를 정의함
loss function은 이루고자 하는 목적의 proxy일 수밖에 없음. 값이 줄어든다고 목적이 수행되는게 아닐 수 있음.
단순히 문제에 맞춰서 손실함수를 사용하는게 아니라, 왜 해당 손실함수를 채택하는지 등을 정확히 이해 및 비교 필요
(ex. 회귀문제 : MSE, 분류문제 : CE, 확률 : MLE...)
4) 최적화 알고리즘 : (Optimization Algorithm) : 네트워크를 어떻게 줄일지? 의 문제
neural network의 파라미터를 Loss function에 의해서 1차 미분한 결과가 stochastic 경사하강법이라면
다양한 momentum, adaptive learning rate 및 기법들을 조정 및 활용하는 법을 알아야 함.
(ex. dropout, early stopping, k-fold validation, weight decay, batch normalization, mixup, ensemble, bayesian optimization 등의 테크닉)
Historical Review
딥러닝 방법론들 중 임팩트가 컸던 방법론들을 중심으로 순서대로 알아보자.
(레퍼런스 : Deep Learning's Most Important Ideas - A brief historical review, Denny Britz)
https://dennybritz.com/posts/deep-learning-ideas-that-stood-the-test-of-time/
1) AlexNet (2012)
- Convolution 이론 네트워크
- 2012년 ISVIC 대회에서 딥러닝 이용 최초로 1등
- 딥러닝의 실질 성능을 입증하면서 ML의 판도 바뀜

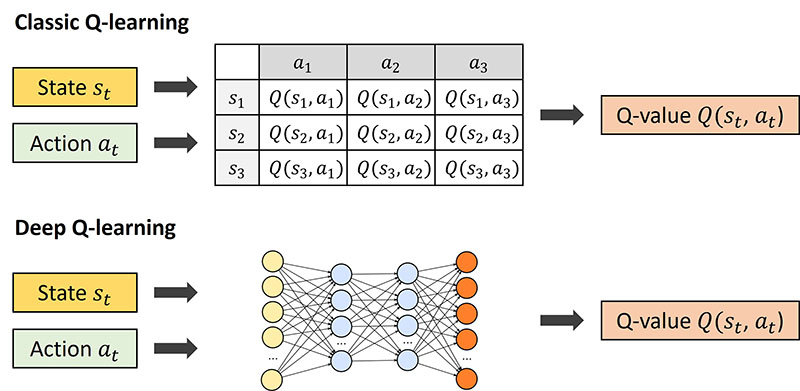
2) DQN (2013)
- 딥러닝을 사용한 강화학습
- Q-learning이라는 강화학습 알고리즘과 심층 신경망을 결합
- 이세돌 vs 알파고 대결에서, 알파고 알고리즘의 기초
- 2013년 Deepmind 연구자들에 의해 소개, 이 이후로 구글에 인수
3-1) Encoder / Decoder (2014)
- NMT(Neural machine translation), 번역 문제를 풀기 위한 목적으로 고안
- 단어의 연속이 encoder에 주어졌을 때, 우리가 원하는 형태의 단어의 연속으로 decoder가 출력하도록 하는 구조

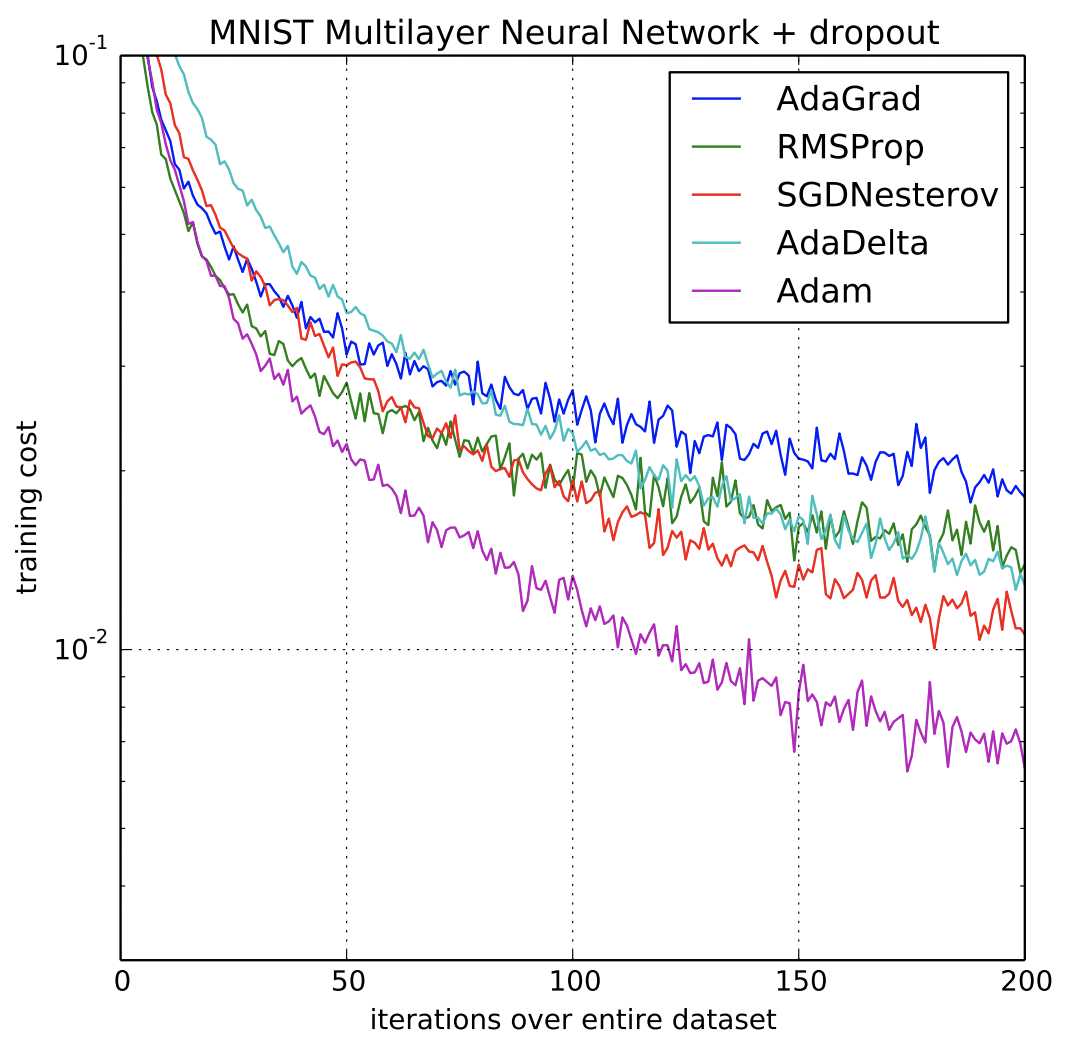
3-2) Adam Optimizer (2014)
- 머신러닝, 딥러닝 사용시 대부분의 경우 다른 optimizer보다 성능 좋은 Adam을 사용
- 연구 논문들을 보면, 특정 optimizer, learning rate, scheduling을 사용한 이유들에 대해서는 밝히지 않음 == 다양한 search들을 통해 최선의 지표들을 발견한다는 뜻
- 일반적으로 적은 resource를 활용하는 연구 환경에서 Adam은 가장 무난한 선택지가 되어준다는 점에서 의미있음
4-1) GAN (2015)
- Generative Adversarial Network 이미지, 텍스트 등을 생성하는 모델
- 네트워크가 Generator, Discriminator 두개를 만들어서 학습을 시키는 방식

4-2) ResNet
- Residual Network
- 이 네트워크를 통해 '왜 딥러닝이 딥러닝인가'를 설명 가능 : shallow network가 아닌 Deep neural network
- 신경망의 layer가 어느정도 이상 깊게 되면 성능이 좋지 않았는데, 깊은 네트워크를 쌓으면서도 성능이 더 좋게 나올 수 있게하는 데 큰 역할을 한 기법
- 딥러닝 네트워크를 깊게 만들때의 그래디언트 소실 문제를 해결하기 위해 제안된 신경망 아키텍처
- 잔차학습 residual learning이 핵심 아이디어 (각 레이어의 입력과 출력 사이에 '잔차'를 학습하여 레이어를 통과하는 동안 원본 입력을 보존함)
- Residual blocks, Skip connections, Deep networks, Transfer learning 등 개념

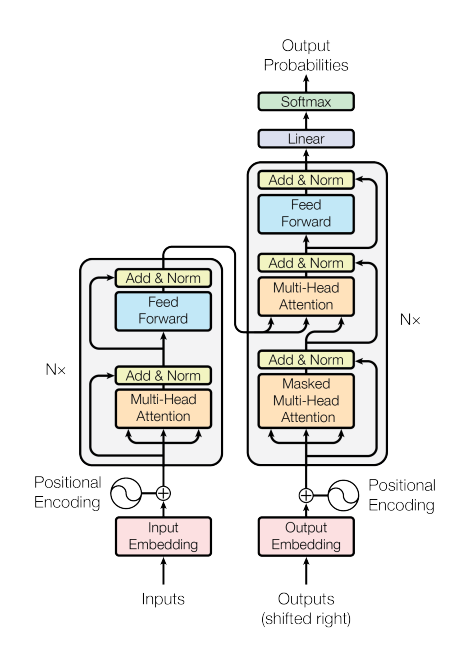
5) Transformer (2017)
- Attention is all you need 논문
- 2017년 논문 발표 이후 BERT, GPT, T5 등 많은 성공적인 NLP 모델들의 기초가 됨
- 이 구조가 타 구조에 비해 어떤 장점이 있고, 왜 성능이 더 좋은지 이해하는 것이 중요
- Input Embedding, Positional Encoding, Encoder/Decoder 개념 등
6) BERT (2018)
- Bidirectional Encoder Representations from Transformers
- 트랜스포머 아키텍처를 기반으로 하며, 특히 양방향으로 텍스트를 이해하는 데 중점
- Fine-tuned NLP 모델 개념의 시작 : 사전학습모델을 특정 데이터로 재학습하는 Fine-tuning 기법을 도입한 연구
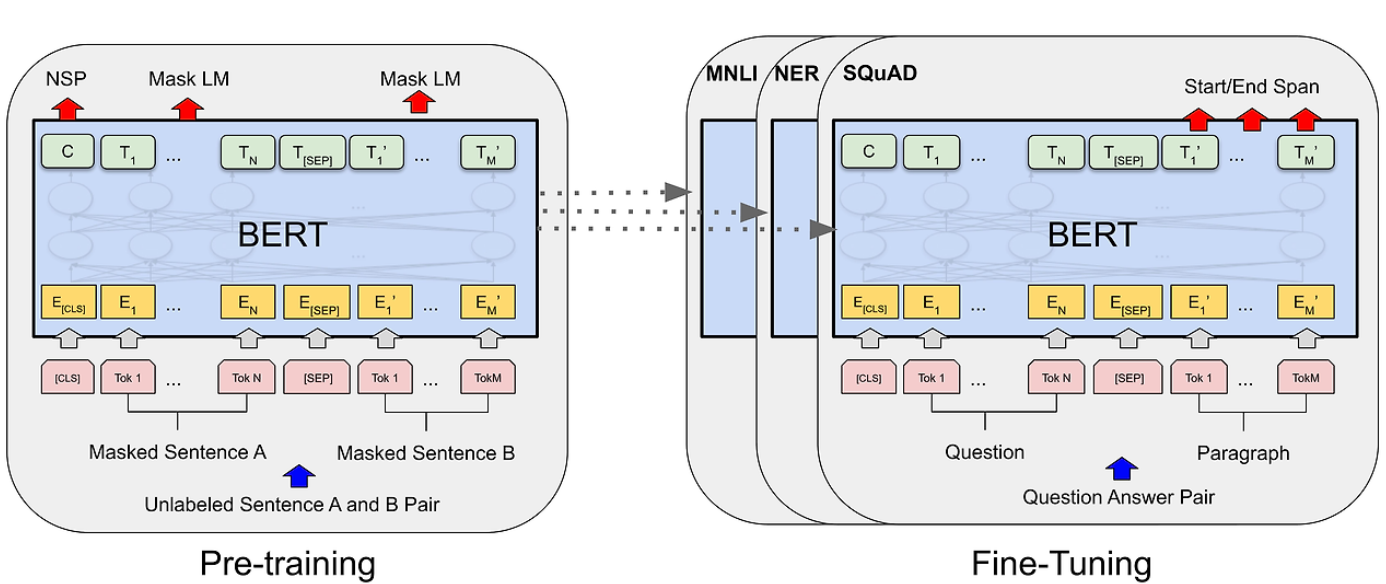
7) Big Language Models - GPT-2~3 (2019)
- OpenAI가 최초 발표한 거대언어모델의 시작
- GPT-3 : autoregressive language model with 175b parameters
- 이후 다양한 거대언어 모델, 생성형 모델들의 등장

8) Self-Supervised learning (2020)
- SimCLR 논문에서 연구 : simple contrastive learning of visual representation
- 이미지 분류와 같은 분류 문제에서, 한정된 학습 데이터 안에서 모델링을 해왔다면, 주어진 학습데이터 이외에 라벨을 모르는 unsupervised 데이터들을 함께 활용해서 모델링하는 방법
- SimCLR이후 다양한 Self suprvised 기법들이 연구되어옴
- 학습데이터를 도메인 지식을 통해 추가로 생성하기도 함

'ML study' 카테고리의 다른 글
| [네이버AI class] 6주차 (3) - 최적화 주요 용어 (0) | 2024.06.03 |
|---|---|
| [네이버AI class] 6주차 (2) - MLP 뉴럴 네트워크 (1) | 2024.06.03 |
| [네이버AI class] 4주차 (1) - 확률론 (0) | 2024.05.21 |
| [네이버AI class] 3주차 (4) 딥러닝 학습 원리 (0) | 2024.05.20 |
| [네이버AI class] 3주차 (3) - 경사하강법 (1) | 2024.05.20 |