Optimization 은 매우 크고 광범위한 주제이지만,
실제 Optimization 작업을 할 때 꼭 알아야 할 개념들을 중심으로만 소개한 내용
1. Gradient Descent
경사 하강법 - 그것이 줄어 들었을때 Optima를 찾을 수 있을 것이라 기대되는 Loss function이 존재하고, 찾고자 하는 파라미터의 편미분을 이용해서 loss function을 줄이는 방향으로 학습을 하는 것
('First-order iterative optimization algrithm for finding a local minimum of a differentiable function)

2. Generalization
많은 경우, 모델의 일반화 성능을 높이는 것이 모델링의 목적이 됨.
Training error가 0에 수렴한다고 좋은게 아닌 이유는, 과적합으로 인해 Training error가 낮아지면 Test error는 높아질 것이기 때문.
아래 그림에서처럼 일반화의 성능은 'Training error 와 Test error간의 차이(gap)' 으로 표현 가능하다.
네트워크의 일반화 성능이 좋다 == 이 네트워크의 성능은 학습데이터의 성능과 비슷하게 나올 것이다.
3. Under-fitting vs Over-fitting
- Over-fitting : 과적합. 학습데이터에 대해서는 성능이 잘 나오지만 테스트데이터에 대해서는 성능이 잘 나오지 않는 모델의 경우
- Under-fitting : 과소적합. 네트워크가 너무 간단하거나 잘못 만들어져서, 학습데이터에 대해서도 성능이 잘 안나오는 모델의 경우
4. Cross Validation
학습데이터와 검증데이터를 나눌 때 활용하는 기법으로, K-fold cross validation(K 폴드 교차검증) 이라고도 함.
학습데이터 전체를 K개로 분리한 후, 분리된 부분을 돌아가면서 검증셋으로 지정, 최종적으로 평균으로 검증 점수를 확인한다.
(이때 테스트 데이터 활용은 금지)
일반적으로, 모델 학습 과정 외부에서 설정되는 값인 최적의 하이퍼파라미터 (learning rate, loss function, estimator 등) 를 결정하기 위해서 Cross validation을 활용한다.
각 하이퍼파라미터 조합에 대해 K개의 모델을 학습하고, 각각의 검증 성능을 평균하여 최종 성능을 평가하는 식.
그리고 그 고정된 하이퍼 파라미터를 활용해서, 최종적으로 모든 데이터를 활용하여 전체 학습을 시켜, 손실 함수를 최소화 하도록 파라미터를 업데이트 해가며 최적해를 찾는다.
5. Bias - Variance trade off
편향과 분산의 개념은 Underfitting, Overfitting 개념과 깊은 연관을 지닌다.
- Bias : 편향. 모델의 예측값이 실제값과 얼마나 다른지를 나타내는 척도이다. 제대로 학습되지 못한 단순한 모델은 높은 편향을 가지며, Underfitting 문제가 발생한다.
- Variance : 분산. 모델이 학습 데이터의 변동에 얼마나 민감하게 반응하는지를 나타내는 척도이다. 학습 데이터의 노이즈까지 학습하여 복잡한 모델은 높은 분산을 가지며, Overfitting 문제가 발생한다.
Bias - Variance는 서로 Tradeoff 관계를 가지는데,
모델의 오류(cost) 를 세 가지 주요 구성 요소로 나눌 수 있기 때문이다 : Bias(편향), Variance(분산), Noise(잡음)
따라서, 모델의 복잡도가 증가함에 따라 Bias는 감소하고 Variance는 증가하는 경향이 있다.
Bias가 적은 모델은 Variance가 높아지는 모델이 되고, Variance가 적은 모델은 Bias가 높아지는 모델이 되기에 둘다 동시에 줄이기 어렵다는 근본적 한계가 있다는 것.
최적의 모델은 이 두 요소의 균형을 맞추어 오류를 최소화하는 모델이 된다.
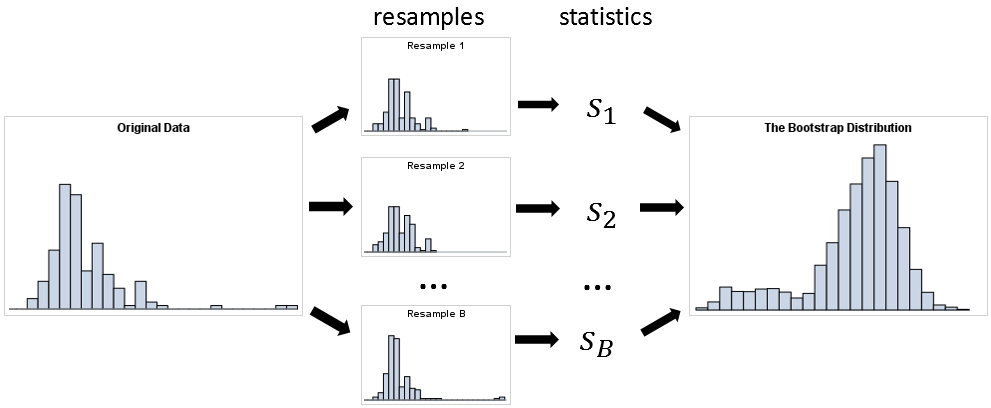
6. Bootstrapping
Bootstrapping이란 subsampling / resampling 기법으로, 데이터셋으로부터 다수의 샘플을 무작위로 복원 추출하여 다양한 통계적 추정치를 계산하는 데 사용된다. ('Bootstrapping is any test or metric that uses random sampling with replacement')
특히 데이터의 크기가 작거나 통계적 추정치의 분포를 추정하기 어려울 때 유용한 기법이다.
ex. 100개 중 80개씩 뽑아서 학습시킨 여러개의 모델을 만들고, 모델간 다양한 예측값들의 consensus를 확인하여 전체적인 모델의 uncertainty 를 확인 가능
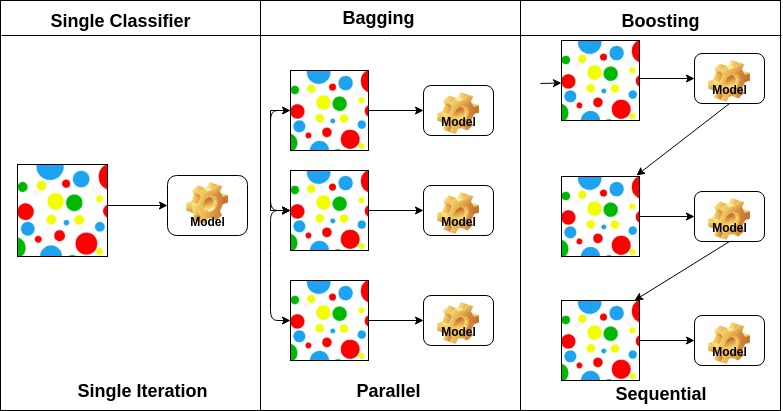
7. Bagging and Boosting
Bagging과 Boosting은 두 가지 중요한 앙상블 학습 기법으로, 여러 개의 모델을 결합하여 성능을 향상시키는 방법이다.
데이터 전체를 모두 한번에 활용하기보다, 샘플링을 통해 학습한 다양한 모델들을 앙상블 하는 것이 더 좋은 성능을 낼 때가 많다.
- Bagging : Parallel한 학습. Bootstrapping Aggregating. 부트스트래핑을 이용해서 여러개의 random subsample 모델을 만들고, 여러 개의 하위 모델을 학습시켜서 이 모델들의 예측을 평균 내거나 다수결 투표를 통해 최종 예측하는 방법이다. (분류 문제에서는 다수결 투표(voting)를, 회귀 문제에서는 평균(averaging)을 통해 최종 예측)
- Boosting : Sequential한 학습. 전체 데이터에 대해 여러 개의 약한 학습자(weak learners)를 순차적으로 학습시키며, 이전 모델이 잘못 예측한 데이터 포인트에 더 많은 가중치를 부여하여 다음 모델이 이를 더 잘 학습하도록 하는 방법이다. 약한 학습자들을 순차적으로 학습시켜 편향을 줄여가며 효과적인 학습이 가능하다.
'ML study' 카테고리의 다른 글
| [네이버AI class] 6주차 (5) - 정규화 (Regularization) (0) | 2024.06.04 |
|---|---|
| [네이버AI class] 6주차 (4) - 경사하강법 & Optimizer 종류 (0) | 2024.06.04 |
| [네이버AI class] 6주차 (2) - MLP 뉴럴 네트워크 (1) | 2024.06.03 |
| [네이버AI class] 6주차 (1) - 딥러닝 기본 및 Historical review (0) | 2024.06.02 |
| [네이버AI class] 4주차 (1) - 확률론 (0) | 2024.05.21 |