본 포스팅에서는 본격적으로 선형 회귀를 활용하여 내용 기반 추천시스템을 만들어보겠다.
내용 기반 추천 시스템의 개념은 아래 포스팅 참고
[RecSys] 2. 내용 기반 추천이란?
내용 기반 추천 (Content-based Recommendation System) 이란? 상품의 속성, 내용 등에 기반하여 상품이 어떤 상품인지를 활용해서 추천하는 방법으로, 이미 유저 선호도가 높은 상품과 유사도가 높은 내용
ysryuu.tistory.com
1. 데이터를 표현하기
- 데이터를 수학적으로 표현하기 위해 : 입력변수 x1...xn, 목표변수 y
- 아래 데이터는 총 4명의 유저에 대해서, 액션(1) 부터 감동(4)까지 총 4개의 속성을 활용하여 영화에 대한 선호도를 표시한 것
- 3번째 유저에 대한 데이터는 아래와 같음 : 속성_1: 0.4, 속성_2: 0.2, 속성_3: 0, 속성_4: 1
- i 번째 데이터의 j번째 속성을 아래와 같이 나타낼 수 있음
$$ x_{2}^{^{(3)}} , x_{j}^{^{(i)}} $$ $$ x^{(3)} = \begin{bmatrix} 0.4 \\ 0.2 \\ 0 \\ 1 \\ \end{bmatrix} $$

2. 다중 선형회귀 모델 학습
내용 기반 추천학습에서, 회귀 모델 학습을 꼭 선형회귀 (Linear Regression)로 수행할 필요는 전혀 없다.
회귀 모델이라면 그 어떤 모델도 활용 가능하나,
여기에서는 추천 시스템을 가장 단순한 형태의 모델로 설명하기 위해서 단일 선형회귀, 다중 선형회귀 모델을 통해 어떻게 추천 시스템을 만들 수 있는지를 설명해보도록 한다.
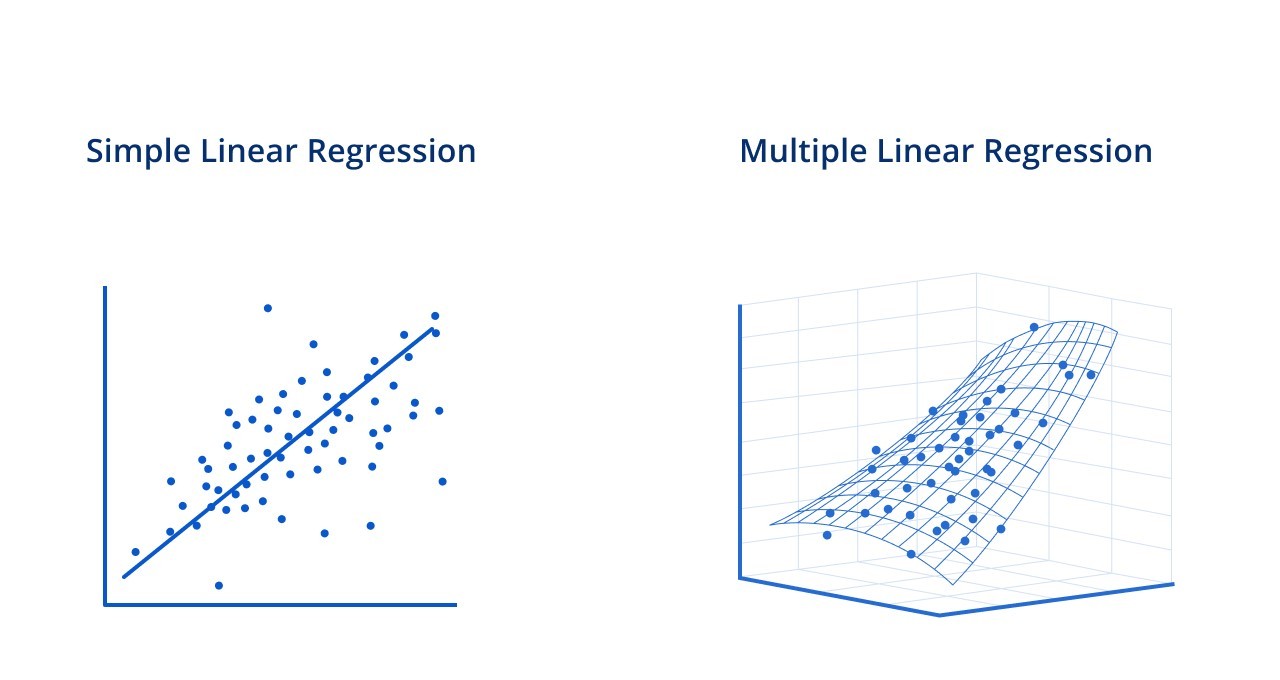
1) Simple Linear Regression (선형 회귀 가설 함수)
하나의 속성에 대해서 영화 선호도 예측값을 도출하는 함수로, 속성 1개 (ex. 로맨스) 즉 하나의 변수를 활용한 일차식 예측이다.
$$ h_{\theta}(x) = \theta _{0} + \theta _{1}x $$
2) Multivariate Linear Regression (다중 선형 회귀 가설 함수)
여러개의 속성에 대해서 영화 선호도 예측값을 도출하는 함수로 아래의 경우 속성 4개 (액션, 로맨스, 코미디, 감동), 다수의 변수를 활용한 일차식 예측이다.
여기에서, \( x \)라는 벡터는 영화의 속성을 나타낸다. : \( x1, x2, x3, x4 \)는 각각 액션 정도, 로맨스 정도, 코미디 정도, 감동 정도 (영화가 실제로 어느정도 각 속성을 지니는지)
또한 \( \theta \) 라는 벡터는 유저의 선호도를 나타낸다. : \(θ1 , θ2, θ3, θ4 \) 는 각각 액션 선호도, 로맨스 선호도, 코미디 선호도, 감동 선호도 (유저가 각 속성을 얼마나 선호하는지)


1), 2) 모두에서 θ의 값들을 조정하면서 최적의 예측을 하는 것이 목표이며, 벡터를 활용하여 아래와 같이 간결한 표현도 가능함.
$$ h_{\theta}(x) = \theta _{0} + \theta _{1}x_{1} + \theta _{2}x_{2} + ... + \theta _{n}x_{n} $$ $$ \theta^{T}x = \theta _{0} + \theta _{1}x_{1} + \theta _{2}x_{2} + ... + \theta _{n}x_{n} $$
아래 두개의 가로 벡터 * 세로 벡터를 서로 곱함으로써 다중 선형회귀를 표현할 수 있는 것.
$$ \theta^T = \begin{bmatrix} \theta_{0} & \theta_{1} & \theta_{2} & ... & \theta_{n} \end{bmatrix} $$ $$\mathbf{x} = \begin{bmatrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{bmatrix}$$
3) 다중 선형회귀 경사하강법
단순 선형회귀 가설 함수, 다중 선형회귀 가설 함수를 평가하는 기준은 무엇일까?
어떻게 선이 그어졌을때, 어떤 함수로 예측이 되었을때 예측을 잘 한 것이라고 알 수 있을까?
(ex. 선형회귀에서 어떤 선이 가장 적절한 예측선일까?)
여기서 중요한 개념이 '손실 함수' 개념.
손실 함수란 주어진 모델의 예측과 실제 타겟 사이의 차이를 측정하는 함수로, 손실 함수가 평균 제곱 오차(Mean Squared Error, MSE)일 경우, 수식은 아래와 같다.
$$ J(\theta) = \frac{1}{2m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)})^2 $$
손실함수가 크면 가설함수가 예측을 잘 못한다는 것이고, 반면 손실함수가 작으면 예측을 잘한다는 것을 의미하므로,
가설 함수에서 경사하강법을 통해 손실을 최소화, 즉 가장 빨리 줄이는 방향으로 \( \theta \) 값들을 바꿔준다.

모든 \( \theta \) 값을 갱신하는 과정을 수식으로 나타내면 아래와 같다. 이때 손실을 최소로 만드는 방향으로 \( \theta \)값을 찾아나감 $$ \begin{align*} \theta_0 & := \theta_0 - \alpha \frac{1}{m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)}) \\ \theta_1 & := \theta_1 - \alpha \frac{1}{m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)})x_1^{(i)} \\ & \vdots \\ \theta_n & := \theta_n - \alpha \frac{1}{m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)})x_n^{(i)} \\ \end{align*} $$
최종적으로 j=0부터 n까지 경사하강법의 업데이트를 간결하게 표현한 것 :
$$ \theta_j := \theta_j - \alpha \frac{1}{m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)}) x_j^{(i)} \quad \text{for } j = 0, 1, \ldots, n $$
3. 유저의 평점 예측
앞선 경사하강법을 통해 theta값을 업데이트 해나가면서, 학습된 결과는 아래 그림처럼 결국 유저별 각 속성에 대한 선호도일 것이다.
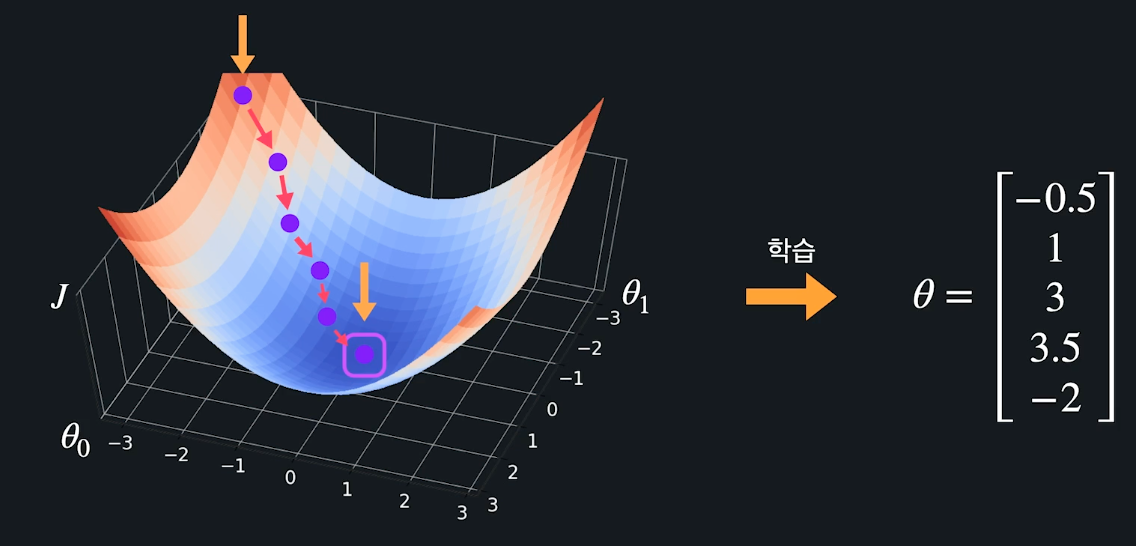
그렇게 도출된 유저별 '취향'은, 유저가 평점 매기지 않았던 새로운 영화의 속성과 계산되면 예측 평점(== 예측 선호도)를 도출할 수 있다.
예를 들어, 아래의 유저의 취향 벡터 * 러브액추얼리 영화의 속성 벡터를 서로 계산하면 4.75가 나온다.
즉 이 유저는 러브액츄얼리를 좋아할 확률이 매우 높을 것이다.

4. 추천
위에서 예측 평점이 높은 영화들을 구할 수 있었다면, 추천은 간단하다.
유저가 평점 매기지 않았고, 예측 평점이 가장 높은 상위 K개의 영화를 추천하면 된다.
위에서는 한명의 유저에 대한 추천만을 설명했지만 선형 회귀를 유저들마다 반복하면서, 각 유저의 평점 예측을 하면 모든 유저에 대한 추천 시스템을 만들 수 있다.
5. 내용 기반 추천의 장단점
장점 :
1. 상품 추천시 다른 유저 데이터가 필요하지 않다
2. 새롭게 출시한 상품, 인기 없는 상품 추천도 가능하다
단점 :
1. 적합한 속성을 고르는 것이 어렵다. 어떤 feature가 중요한 feature일 것인가?
2. 속성값 선택이 주관적으로 선정될 수 있다
3. 유저가 준 데이터를 벗어나는 추천, 유저의 행동범위를 벗어나는 추천을 하기가 어렵다.
4. 인기, 유행 상품들 및 다른 사람들이 좋게 평가한 상품을 추천하기 어렵다.
* 참고
- 경사하강법 관련 수학 https://medium.com/swlh/the-math-of-machine-learning-i-gradient-descent-with-univariate-linear-regression-2afbfb556131
The Math of Machine Learning I: Gradient Descent With Univariate Linear Regression
Addressing the mathematics head-on in the simplest possible use case.
medium.com
Implementing the Steepest Descent Algorithm in Python from Scratch
Table of contents
towardsdatascience.com
'ML system' 카테고리의 다른 글
| [RecSys] 5. 협업 필터링 기반 추천시스템 만들기 - 이론편1 (feat.유사도) (0) | 2024.04.30 |
|---|---|
| [RecSys] 4. 협업 필터링이란? (0) | 2024.04.23 |
| [RecSys] 2. 내용 기반 추천이란? (0) | 2024.04.23 |
| [RecSys] 1. 추천 시스템이란? (0) | 2024.04.23 |