행렬의 개념
행렬이란?
행렬은 벡터를 원소로 가지는 2차원 배열이다.
행렬에는 행과 열이 있다.
벡터처럼 np.array로 나타낼 수 있는데, 아래처럼 numpy에서는 행벡터를 원소로 가지는배열 array으로 정의한다.
행렬의 특정 행을 고정하면 행벡터, 특정 열을 고정하면 열벡터라 부른다.
행렬을 확장해서 n개의 행 벡터 * m 개의 성분으로 이루어지는 배열로 볼 수 있다. (n x m 행렬)
행렬은 대문자 볼드체로 (A) 표시하기도, 소문자 행렬을 함께 나타내어 표시하기도(aij) 한다.
A = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
전치 행렬 (Transpose Matrix)
전치행렬이란 행과 열의 인덱스가 바뀐 행렬이다. Xij 가 Xji가 되는 것.
주로 행렬의 우측 상단에 T기호를 적어줌으로써 요소의 모든 행렬을 서로 전치시켰음을 표시한다.
m개의 행, n개의 열로 이루어진 행렬은 n개의 행과 m개의 열로 이루어진 행렬로 바뀐다.
벡터에 전치행렬을 씌우게 되면, 행벡터는 열벡터로, 열벡터는 행벡터로 바뀐다.
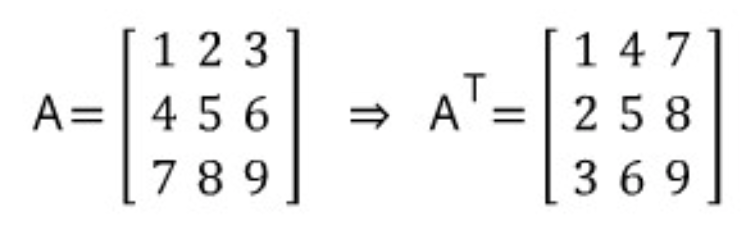
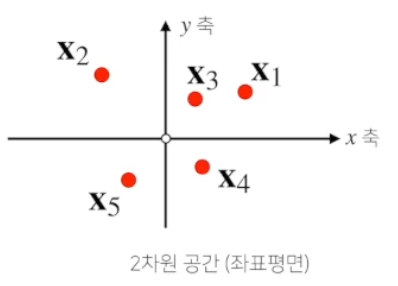
* 행렬의 이해 - 1) 공간상 행렬 (데이터들의 모임)
벡터가 하나의 점을 의미했다면, 행렬은 공간상에서 여러개의 점으로 이해할 수 있다.
행렬이 여러개의 '행벡터'를 포함하는 개념이므로, 각각의 행벡터가 공간상에 표현되어 다수의 점이 있는 것으로 보면 된다.
행렬은 곧 어떤 데이터들의 모임
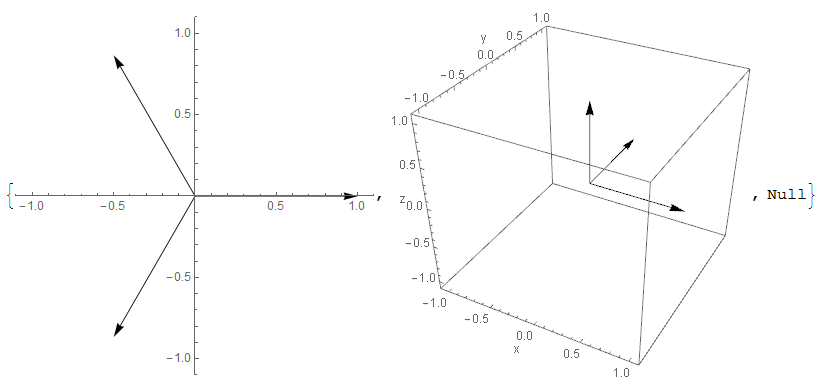
* 행렬의 이해 - 2) 벡터 공간의 연산자 (Operator)
행렬 자체가 데이터라기 보다는, 데이터를 서로 연결시키는 연산자로 이해할 수도 있다.
m차원 공간상의 점 x와 n차원 공간상의 점 y를 서로 연결시킨다는 개념
행렬 A와 벡터 X사이의 곱의 결과로 Z를 산출 : m차원 공간의 X 벡터를 n차원 공간의 Z 벡터로 맵핑할 수 있다.
== 행렬 곱을 통해서 벡터를 다른 차원의 공간으로 보낼 수 있다.
== 모든 선형변환 linear transformation은 행렬 곱으로 나타낼 수 있다.
이런 행렬 곱을 통해서 패턴을 추출하고 데이터를 압축하는 것도 가능하다.
딥러닝은 특히 모두 선형 함수 및 비선형 함수들의 합성으로 이루어져있기 때문에, 기본적으로 행렬곱 개념을 정확히 이해해야 한다.


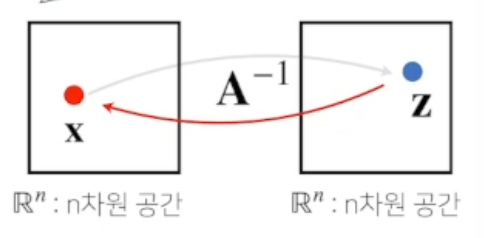
역행렬 (Inverse Matrix)
역행렬이란 어떤 행렬 A 의 연산을 거꾸로 되돌리는 행렬이다.
앞서 행렬 연산이 벡터를 n차원 공간에서 m차원 공간으로 이동시키는 역할을 했다면,
역행렬은 그 이동을 되돌리는 역할을 한다.
역행렬은 행과 열 숫자가 같고 행렬식(determinant)이 0이 아닌 경우에만 계산할 수 있다.
역행렬 연산은 n = m일때만 성립한다. (행과 열의 숫자가 동일해야 한다)
행렬 A와 A의 역행렬을 곱하면 항등행렬이 된다. (항등행렬 : 임의의 벡터를 곱했을때 자기 자신이 나오는 행렬)


import numpy as np
# 예시 행렬 정의
matrix = np.array([[1, 2], [3, 4]]) # 행과 열의 개수가 동일
# 역행렬 계산
try:
inverse_matrix = np.linalg.inv(matrix)
print("Inverse matrix:")
print(inverse_matrix)
except np.linalg.LinAlgError:
print("This matrix is singular and does not have an inverse.")
# 결과
Inverse matrix:
[[-2. 1. ]
[ 1.5 -0.5]]
# 행렬 * 역행렬을 곱한 결과 == 항등행렬
Matrix multiplied by its inverse:
[[ 1.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 1.00000000e+00]]
유사 역행렬 (Pseudo-inverse Matrix)
역행렬이 성립하기 위한 조건(행, 열 개수 일치 및 determinant 0아님) 이 까다롭기 때문에, 역행렬을 계산할 수 없는 경우가 있다.
만약 역행렬을 계산할 수 없다면, 유사역행렬 (pseudo-inverse) 또는 무어펜로즈(moore-penrose) 역행렬을 이용한다.
마이너스 기호가 아닌 플러스 기호를 활용해서 역행렬과 유사 기능을 수행하는 행렬을 구할 수 있다.
머신러닝 딥러닝에서 역행렬을 구하는 연산은 매우 중요한 개념.

주의할 점으로, 행의 개수가 더 많을 때, 열의 개수가 더 많을때 각각의 경우 구하는 공식이 다르다. (전치행렬을 곱하는 순서가 달라짐)
행렬과 유사 역행렬을 서로 곱할때도, 순서가 중요하다. 곱셈의 순서가 바뀌면 결과값도 달라짐.
- n >= m인 경우, (행이 열보다 클 때) 유사역행렬(A+) 을 행렬(A) 보다 더 먼저 곱해줘야 하며,
- n <= m인 경우, (열이 행보다 클 때) 행렬(A)을 유사역행렬(A+) 보다 더 먼저 곱해줘야 한다.
import numpy as np
# 예시 행렬 정의 (정사각 행렬이 아니거나 특이 행렬)
matrix = np.array([[1, 2, 3], [4, 5, 6]])
# 무어-펜로즈 역행렬 계산
pseudo_inverse_matrix = np.linalg.pinv(matrix) # pseudo-inverse
print("Moore-Penrose Pseudo-Inverse matrix:")
print(pseudo_inverse_matrix)
# 원본 행렬과 유사 역행렬을 곱한 결과 확인
identity_approx = np.dot(matrix, pseudo_inverse_matrix)
print("Original matrix multiplied by its pseudo-inverse:")
print(identity_approx)
# 결과
Moore-Penrose Pseudo-Inverse matrix:
[[-6.94444444e-01 3.61111111e-01]
[-5.55555556e-02 1.66666667e-02]
[ 5.83333333e-01 -3.27777778e-01]]
# 행렬과 유사 역행렬을 곱해 거의 항등행렬과 유사한 결과 확인
Original matrix multiplied by its pseudo-inverse:
[[ 1.00000000e+00 2.22044605e-16]
[-1.11022302e-16 1.00000000e+00]]
행렬의 연산
같은 모양을 가지는 행렬끼리는 덧셈, 뺄셈을 계산 가능하다. (벡터와 마찬가지)
행렬의 성분곱, 스칼라곱 또한 벡터와 같은 개념이다.
1) 행렬의 곱셈
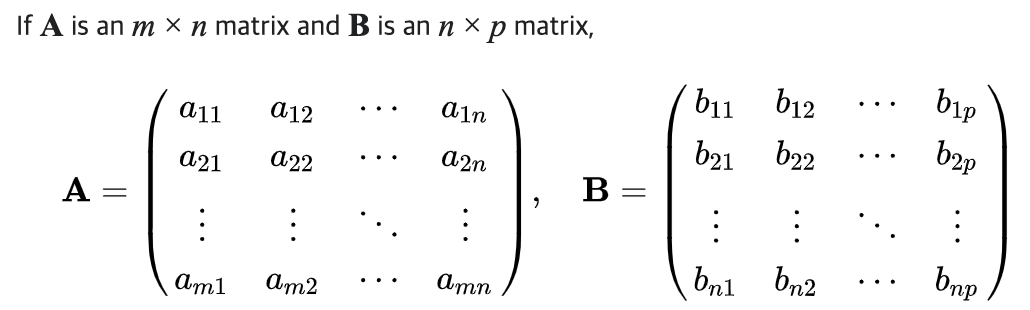
행렬의 곱셈 (Matrix Multiplication) 은 X 행렬의 i번째 행벡터와, Y 행렬의 열벡터 사이의 내적을 성분으로 가지는 행렬을 계산한다.
행렬의 곱셈에서는 곱해지는 순서가 중요하기 때문에, XY 곱과 YX 곱의 결과는 완전히 다름.
두 행벡터, 열벡터 사이 내적을 구하기 위해서는 벡터의 차원이 같아야 하므로, XY 행렬곱을 할때, X 행렬의 행벡터와, Y 행렬의 열벡터의 원소의 개수는 동일해야 한다.

A = [
[1, 2, 3],
[4, 5, 6]
]
B = [
[7, 8],
[9, 10],
[11, 12]
]
# 행렬 곱셈 함수
def matrix_multiply(A, B):
# A의 행 개수, B의 열 개수
m = len(A)
n = len(A[0])
p = len(B[0])
# 결과 행렬 초기화 (m x p 크기)
C = [[0] * p for _ in range(m)]
# 행렬 곱셈 수행
for i in range(m):
for j in range(p):
for k in range(n):
C[i][j] += A[i][k] * B[k][j]
return C
# 행렬 곱셈 수행
C = matrix_multiply(A, B) # A@B 와도 동일함
# 결과 출력
for row in C:
print(row)
# 결과
[58, 64]
[139, 154]
2) np.inner 내적
넘파이의 np.inner은 i번째 행벡터와 j번째 행벡터를 성분으로 가지는 행렬을 계산한다
(행렬의 곱에서 i번째 행벡터와 j번째 열벡터를 계산하는 것과는 다르니 주의! 수학의 내적과 다른 개념이다)
이 경우에는 두 행렬의 행의 개수가 같아야 한다.
import numpy as np
# 두 행렬 정의 (행 개수 동일)
A = np.array([
[1, 2, 3],
[4, 5, 6]
])
B = np.array([
[7, 8, 9],
[10, 11, 12]
])
# np.inner 사용하여 각 행의 내적 계산
inner_product = np.inner(A, B)
# 결과 출력
print(inner_product)
3) 연립방정식 풀기 (simultaneous equation)
유사역행렬을 이용해서 np.linalg.pinv 연립방정식을 풀 수 있다.
아래 수식에서 Ax = b라는 연립방정식을 확인할 수 있다.
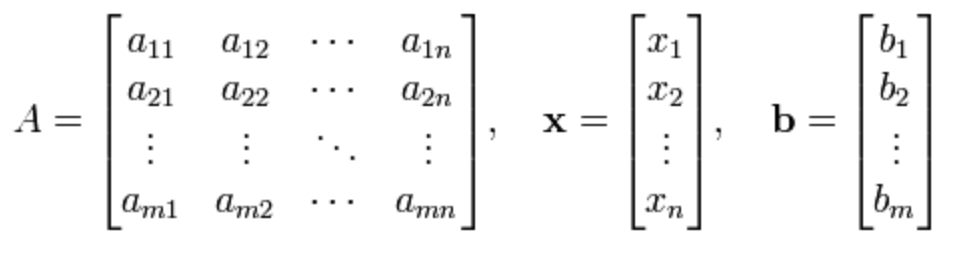
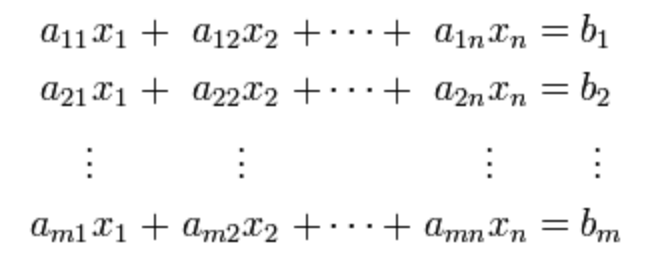
위의 연립방정식에서 만약 n <= m일 경우, 무어펜로즈 역행렬을 활용해 아래와 같이 해를 구하는 것이 가능하다.

import numpy as np
# 연립방정식의 계수 행렬 (A), 상수 벡터 (b) 정의
A = np.array([[1, 2], [3, 4], [5, 6]])
b = np.array([5, 7, 9])
A * x = b
# 무어-펜로즈 역행렬 계산
A_pseudo_inv = np.linalg.pinv(A)
# 해 계산: x = A^+ * b
x = np.dot(A_pseudo_inv, b)
print("Solution:")
print(x)
4) 선형회귀 분석 (Linear regresson)
유사역행렬을 이용해서 np.linalg.pinv 데이터를 선형 모델 (linear model)로 해석하는 선형회귀식을 찾을 수 있다.
연립방정식 수식에서 Ax = b라는 식이 성립했다면, 선형 모델에서는 X β = y 로, X와 y가 주어진 상황에서 계수 β 를 구해야 한다.
연립방정식과 마찬가지로, n과 m이 동일하지 않다면, 방정식 X β = y 을 푸는 것은 정확히 불가능하지만,
L2 norm을 이용해서 역행렬을 통해 y에 근접하는 값을 찾을 수 있다. 이때 찾은 β를 최적해라고 볼 수 있다.


아래 코드는 선형회귀의 계수 β를 구하는 식으로, 사이킷런의 선형회귀 모듈과 무어펠로즈 방법으로 각각 계수를 구할 수 있다.
import numpy as np
# 입력 데이터 X와 타겟 데이터 y 정의
X = np.array([[1, 2], [3, 4], [5, 6]])
y = np.array([3, 5, 7])
# 테스트 데이터 x_test 정의
x_test = np.array([[7, 8], [9, 10]])
# 사이킷런으로 회귀 분석
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X,y)
y_test_1 = model.predict(x_test)
# 무어-펜로즈 역행렬
X_ = np.array([np.append(x,[1]) for x in X]) # y절편을 직접 추가 필요
beta = np.linalg.pinv(X_) @ y
y_test_2 = np.append(x_test) @ beta
print("사이킷런을 사용한 회귀 분석 결과:", y_test_1)
print("무어-펜로즈 역행렬을 사용한 회귀 분석 결과:", y_test_2)
'ML study' 카테고리의 다른 글
| [네이버AI class] 3주차 (4) 딥러닝 학습 원리 (0) | 2024.05.20 |
|---|---|
| [네이버AI class] 3주차 (3) - 경사하강법 (1) | 2024.05.20 |
| [네이버AI class] 3주차 (1) - 벡터 (0) | 2024.05.16 |
| [네이버AI class] 1주차 - 개발 환경 설정, Pandas, Numpy (0) | 2024.05.05 |
| [MLstudy] 1. 피처 엔지니어링 - 1) 피처 정규화 (0) | 2024.04.24 |