* 프로그래머스의 마키나락스 MLOPS 강의를 참고하여 작성함
이제 저장한 모델을 불러와서 불러온 데이터로 predict 해보도록 하겠다.
모델을 저장하는 방법에 대해서는 지난 포스팅의 실습을 참고
[MLOps] 17. 모델 저장하기 실습
이제 모델을 저장소에 저장하는 실습을 해보도록 한다. 모델의 저장 방법 및 구조 (docker compose)에 대해서는 이전 포스팅 참고https://ysryuu.tistory.com/36 <figure id="og_1714455657587" data-og-image="https://scrap.
ysryuu.tistory.com
모델 불러오기 방법
저장된 모델을 불러오는 코드는 두가지가 있다.
1. Sklearn 모듈의 load_model 활용
def load_sklearn_model(run_id, model_name) :
clf = mlflow.sklearn.load_model(f'runs:/{run_id}/{model_name}')
return clf
2. Pyfunc 모듈의 load_model 활용
def load_pyfunc_model(run_id, model_name):
clf = mlflow.pyfunc.load_model(f'runs:/{run_id}/{model_name}')
return clf
두 load_model 방법의 차이?
우선 두가지 방법의 기본적인 차이라면, 로드할 모델의 유형이 다를 수 있다.
- sklearn 모듈의경우 Scikit-learn 모델에 특화되어 있어, 주로 MLflow에 저장된 Scikit-learn 모델을 로드하는 데 사용된다.
- pyfunc 모듈의 경우 PyFunc 형식은 Python 함수로 모델을 포장하기 때문에 모델 유형에 제한이 없고, MLflow로 추적된 모든 모델을 로드하는 데 사용된다는 점이 다르다.
아래 모델 로드 실습에서는 sklearn, pyfunc 두개의 모듈로 모델을 각각 불러오고 추론하여 비교해 보는 파일을 작성해보도록 한다.
모델 로드 파일 작성
1. 환경 설정 부분
import os
import json
import mlflow
import pandas as pd
from minio import Minio
BUCKET_NAME = 'raw-data'
OBJECT_NAME = 'iris'
os.environ['MLFLOW_S3_ENDPOINT_URL'] = 'http://0.0.0.0:9000' # minio
os.environ['MLFLOW_TRACKING_URI'] = 'http://0.0.0.0:5001' # mlflow
os.environ['AWS_ACCESS_KEY_ID'] = 'minio' # minio (aws s3) id
os.environ['AWS_SECRET_ACCESS_KEY'] = 'miniostorage' # minio (aws s3) password
...
2. 데이터를 불러오는 부분
def download_data():
with open('credentials.json','r') as f :
credentials = json.load(f)
url = credentials['url'].replace('http://','')
access_key = credentials['accessKey']
secret_key = credentials['secretKey']
client = Minio(url, access_key=access_key, secret_key=secret_key, secure=False)
object_stat = client.stat_object(BUCKET_NAME, OBJECT_NAME)
data_version_id = object_stat.version_id
client.fget_object(bucket_name=BUCKET_NAME, object_name=OBJECT_NAME, file_path='download_data.csv')
return data_version_id
def load_data():
data_version_id = download_data()
df = pd.read_csv('download_data.csv')
X,y = df.drop(columns='target'), df['target']
data_dict = {'data':X, 'target':y, 'version_id':data_version_id}
return data_dict
3. 모델 불러오기
def load_sklearn_model(run_id, model_name):
clf = mlflow.sklearn.load_model(f'runs:/{run_id}/{model_name}')
return clf
def load_pyfunc_model(run_id, model_name):
clf = mlflow.pyfunc.load_model(f'runs:/{run_id}/{model_name}')
return clf
4. 불러온 데이터, 모델로 추론하기
if __name__ == '__main__':
from argparse import ArgumentParser
parser = ArgumentParser()
parser.add_argument('--run-id',type=str)
parser.add_argument('--model-name', type=str, default='my_model')
args = parser.parse_args()
data_dict = load_data()
X = data_dict['data']
sklearn_clf = load_sklearn_model(args.run_id, args.model_name)
sklearn_pred = sklearn_clf.predict(X)
print('sklearn load model: ')
print(sklearn_clf)
print(sklearn_pred)
pyfunc_clf = load_pyfunc_model(args.run_id, args.model_name)
pyfunc_pred = pyfunc_clf.predict(X)
print('pyfunc load model: ')
print(pyfunc_clf)
print(pyfunc_pred)
완성된 코드
완성된 코드는 아래와 같다.
<load_model.py 파일 내용>
import os
import json
import mlflow
import pandas as pd
from minio import Minio
# 변수부
BUCKET_NAME = 'raw-data'
OBJECT_NAME = 'iris'
os.environ['MLFLOW_S3_ENDPOINT_URL'] = 'http://0.0.0.0:9000' # minio
os.environ['MLFLOW_TRACKING_URI'] = 'http://0.0.0.0:5001' # mlflow
os.environ['AWS_ACCESS_KEY_ID'] = 'minio' # minio (aws s3) id
os.environ['AWS_SECRET_ACCESS_KEY'] = 'miniostorage' # minio (aws s3) password
# 함수부
def download_data():
with open('credentials.json','r') as f :
credentials = json.load(f)
url = credentials['url'].replace('http://','')
access_key = credentials['accessKey']
secret_key = credentials['secretKey']
client = Minio(url, access_key=access_key, secret_key=secret_key, secure=False)
object_stat = client.stat_object(BUCKET_NAME, OBJECT_NAME)
data_version_id = object_stat.version_id
client.fget_object(bucket_name=BUCKET_NAME, object_name=OBJECT_NAME, file_path='download_data.csv')
return data_version_id
def load_data():
data_version_id = download_data()
df = pd.read_csv('download_data.csv')
X,y = df.drop(columns='target'), df['target']
data_dict = {'data':X, 'target':y, 'version_id':data_version_id}
return data_dict
def load_sklearn_model(run_id, model_name):
clf = mlflow.sklearn.load_model(f'runs:/{run_id}/{model_name}')
return clf
def load_pyfunc_model(run_id, model_name):
clf = mlflow.pyfunc.load_model(f'runs:/{run_id}/{model_name}')
return clf
# 실행부
if __name__ == '__main__':
from argparse import ArgumentParser
parser = ArgumentParser()
parser.add_argument('--run-id',type=str)
parser.add_argument('--model-name', type=str, default='my_model')
args = parser.parse_args()
data_dict = load_data()
X = data_dict['data']
sklearn_clf = load_sklearn_model(args.run_id, args.model_name)
sklearn_pred = sklearn_clf.predict(X)
print('sklearn load model: ')
print(sklearn_clf)
print(sklearn_pred)
pyfunc_clf = load_pyfunc_model(args.run_id, args.model_name)
pyfunc_pred = pyfunc_clf.predict(X)
print('pyfunc load model: ')
print(pyfunc_clf)
print(pyfunc_pred)
모델 불러오기 실습
이제 본격적으로 모델을 불러와서 실행해보도록 하겠다.
1. 모델의 정보 확인
모델 로드 파일을 실행하기 이전에, 우선 어떤 모델을 불러올지 결정하고
MLflow 사이트에서 불러올 모델의 run_id, model_name을 확인해야 한다.
http://0.0.0.0:5001 사이트에서 확인해보자
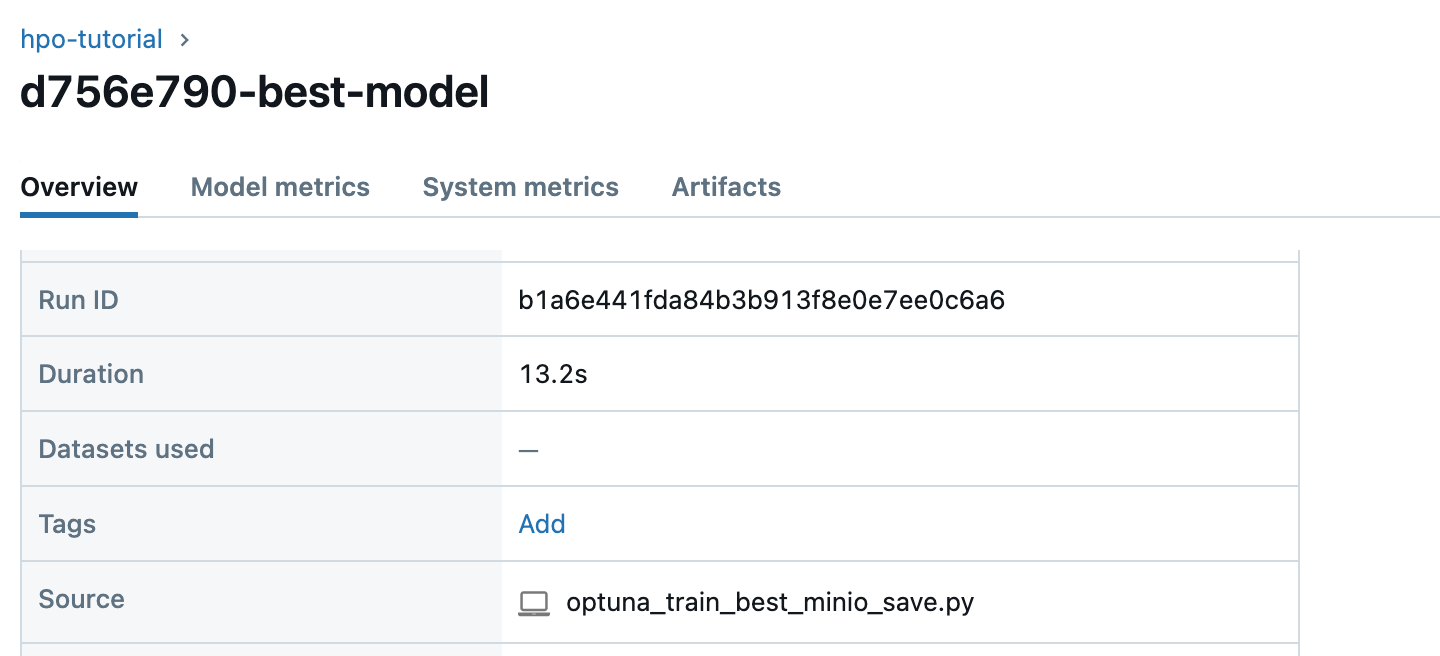
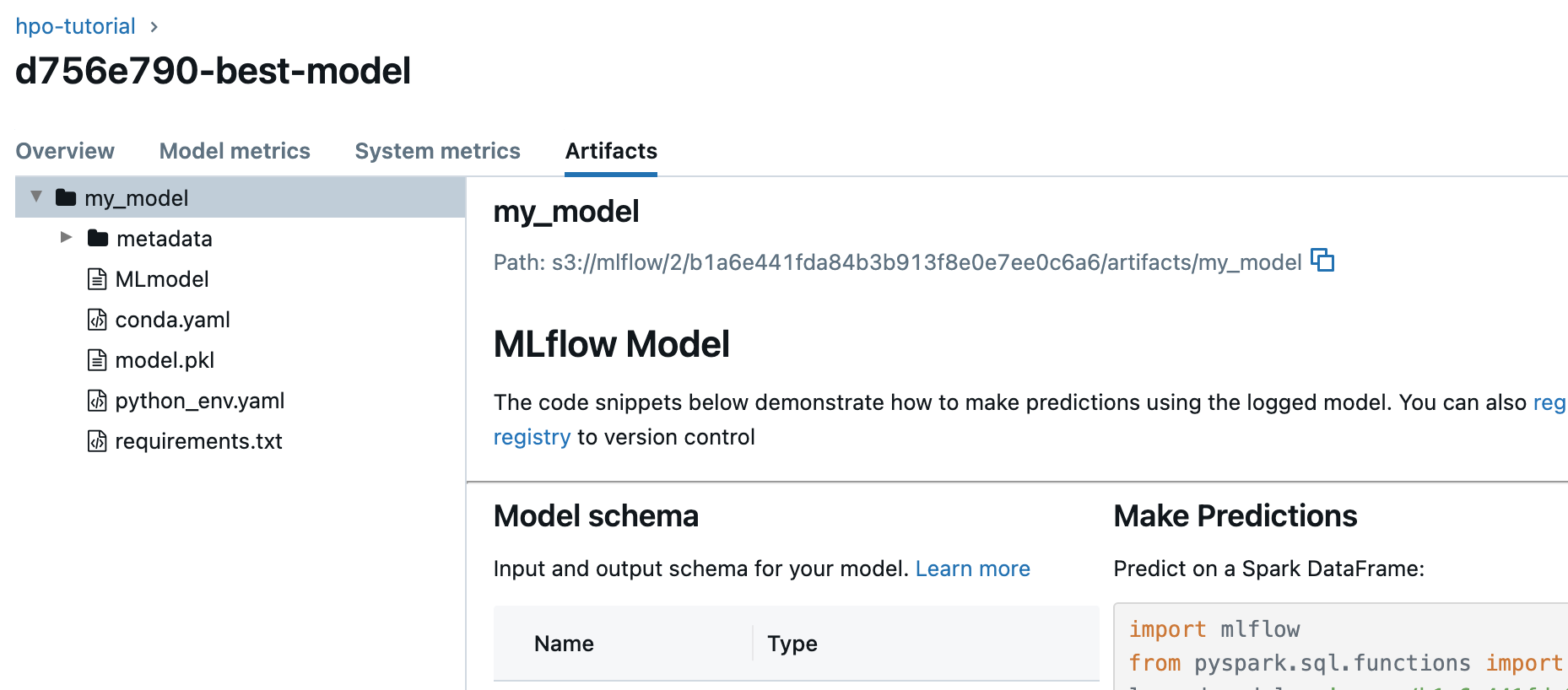
hpo-tutorial 실험에서 저장된 모델 (sklearn)을 클릭하면, overview 란에서 Run ID를 확인 가능하고,
artifact 란에서 my_model이라는 폴더에 모델 정보인 artifact가 저장 되어있음을 확인 가능하다.
2. 터미널에서 파일 실행하기
위에서 MLflow 사이트에서 확인한 run_id를 적용하여 아래처럼 모델을 불러오는 파일을 실행해준다
그 결과 sklearn model , pyfunc model 의 방식으로 각각 모델이 불러와지고 예측한 값을 확인할 수 있다.
$ python load_model.py --run_id b1a6e441fda84b3b913f8e0e7ee0c6a6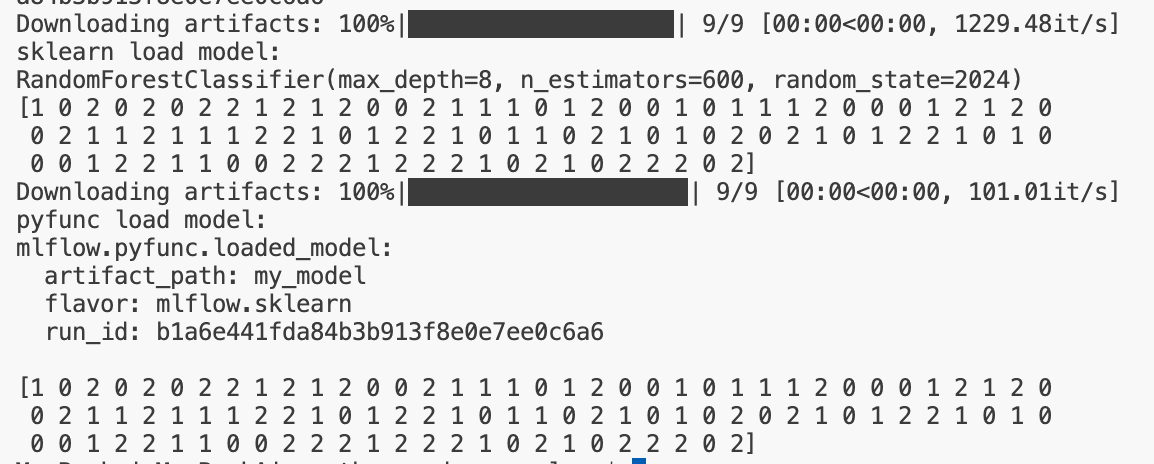
'MLOps' 카테고리의 다른 글
| [MLOps] 19. Pyfunc 사용하기 (feat.커스텀 모델 만들기) (0) | 2024.04.30 |
|---|---|
| [MLOps] 17. MLflow에 모델 저장하기 실습 (0) | 2024.04.30 |
| [MLOps] 16. 모델 저장소 구축 방법 (feat. 도커 컴포즈) (0) | 2024.04.30 |
| [MLOps] 13. MinIO 사용하기 (구축, data 업로드&다운로드) (0) | 2024.04.30 |
| [MLOps] 14. 모델 파일에 MinIO 반영 및 실행 (0) | 2024.04.30 |